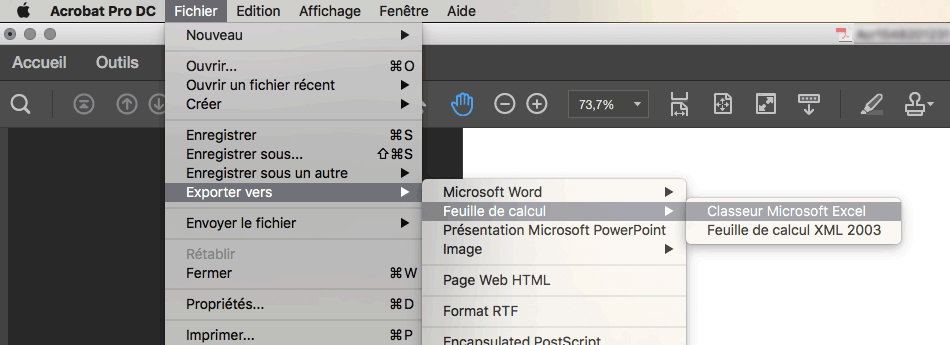
bonjour,
je viens de recevoir un tableau enregistré sous PDF.
Je souhaiterais récupérer ce tableau pour le mettre sous Excel.
Avez-vous une soution ????
Merci
je viens de recevoir un tableau enregistré sous PDF.
Je souhaiterais récupérer ce tableau pour le mettre sous Excel.
Avez-vous une soution ????
Merci

")