M
Membre supprimé 1129907
Invité
Ceci devrait fonctionner. Cela recherchera tous les fichiers présents dans ton dde dans le répertoire "Musique_ok".
Ensuite, il se sert des noms des dossiers pour le rajouter dans le nom du fichier. Il traitera tous les fichiers sauf les ".DS_Store"
Cas 1
"./artiste/album/fichier" deviendra "artiste - album - fichier"
Cas 2
"./dossier/fichier" deviendra "dossier - fichier"
Et à la fin, je t'ai fait une petite détection des fichiers qui semblent être des doublons.
Tu auras 3 fichiers txt créés avant le répertoire Musique_ok:
La partie
est à remplacer par
une fois que c'est lancé une première fois sans erreur et que tu as vérifié que le résultat te convient bien.
La version de base ne traitera que 10 fichiers et en fera une copie. Après la modification, cela traitera bien tous les fichiers et les déplacera (pas de copie)
Ensuite, il se sert des noms des dossiers pour le rajouter dans le nom du fichier. Il traitera tous les fichiers sauf les ".DS_Store"
Cas 1
"./artiste/album/fichier" deviendra "artiste - album - fichier"
Cas 2
"./dossier/fichier" deviendra "dossier - fichier"
Et à la fin, je t'ai fait une petite détection des fichiers qui semblent être des doublons.
Tu auras 3 fichiers txt créés avant le répertoire Musique_ok:
- liste_musique.txt : la liste de tous les fichiers trouvés dans "Musique_ok" et qui seront donc renommés
- liste_musique_doublon_1.txt : le résultat des cksum de ces fichiers (est fait après leur déplacement)
- liste_musique_doublon_2.txt : les fichiers dont le cksum est identique
Bloc de code:
#!/bin/bash
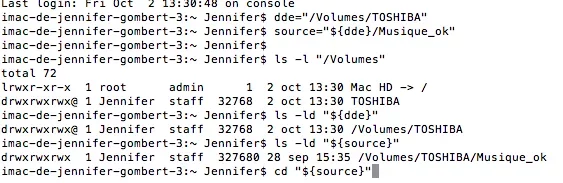
dde="/Volumes/TOSHIBA"
source="${dde}/Musique_ok"
liste_fic="${dde}/liste_musique.txt"
liste_fic_sort1="${dde}/liste_musique_doublon_1.txt"
liste_fic_sort2="${dde}/liste_musique_doublon_2.txt"
if [ ! -d "${source}" ] ; then echo error ; exit 1 ; fi
cd "${source}"
find . -type f | grep -v ".DS_Store" | head 10 > "${liste_fic}"
while IFS= read -r fichier_full
do
fichier_new=$(echo ${fichier_full} | sed "s#^\./##" | sed "s#/# - #g")
cp "${fichier_full}" "${fichier_new}"
done < "${liste_fic}"
#detection doublon
#936731427 13791 listemusique.txt
#936731427 13791 test.txt
cksum "${source}/*.*" | sort > "${liste_fic_sort1}"
cut -d' ' -f 1,2 "${liste_fic_sort1}" | uniq -d | while IFS= read -r fichier_cksum
do
egrep "^${fichier_cksum} " "${liste_fic_sort1}"
echo ""
done > "${liste_fic_sort2}"La partie
Bloc de code:
find . -type f | grep -v ".DS_Store" | head 10 > "${liste_fic}"
while IFS= read -r fichier_full
do
fichier_new=$(echo ${fichier_full} | sed "s#^\./##" | sed "s#/# - #g")
cp "${fichier_full}" "${fichier_new}"
done < "${liste_fic}"
Bloc de code:
find . -type f | grep -v ".DS_Store" > "${liste_fic}"
while IFS= read -r fichier_full
do
fichier_new=$(echo ${fichier_full} | sed "s#^\./##" | sed "s#/# - #g")
mv "${fichier_full}" "${fichier_new}"
done < "${liste_fic}"La version de base ne traitera que 10 fichiers et en fera une copie. Après la modification, cela traitera bien tous les fichiers et les déplacera (pas de copie)




")